Mettre en place une communication intra-process efficace
Table des matières
Arrière-plan
Les applications ROS consistent généralement en une composition de « nœuds » individuels qui effectuent des tâches étroites et sont découplés des autres parties du système. Cela favorise l’isolation des pannes, un développement plus rapide, la modularité et la réutilisation du code, mais cela se fait souvent au détriment des performances. Après le développement initial de ROS 1, le besoin d’une composition efficace des nœuds est devenu évident et des Nodelets ont été développés. Dans ROS 2, nous visons à améliorer la conception des Nodelets en résolvant certains problèmes fondamentaux nécessitant une restructuration des nœuds.
Dans cette démo, nous mettrons en évidence la manière dont les nœuds peuvent être composés manuellement, en définissant les nœuds séparément mais en les combinant dans différentes dispositions de processus sans modifier le code du nœud ni limiter ses capacités.
Installation des démos
Consultez les instructions d’installation pour plus de détails sur l’installation de ROS 2.
Si vous avez installé ROS 2 à partir de packages, assurez-vous que ros-rolling-intra-process-demo est installé. Si vous avez téléchargé l’archive ou construit ROS 2 à partir de la source, cela fera déjà partie de l’installation.
Exécution et compréhension des démos
Il existe quelques démos différentes : certaines sont des problèmes de jouets conçus pour mettre en évidence les fonctionnalités de la fonctionnalité de communication intra-processus et d’autres sont des exemples de bout en bout qui utilisent OpenCV et démontrent la capacité de recombiner des nœuds dans différentes configurations.
La démonstration du pipeline à deux nœuds
Cette démonstration est conçue pour montrer que la connexion de publication/abonnement intra-processus peut entraîner un transport sans copie des messages lors de la publication et de l’abonnement avec std::unique_ptrs.
Voyons d’abord la source :
#include <chrono>
#include <cinttypes>
#include <cstdio>
#include <memory>
#include <string>
#include <utility>
#include "rclcpp/rclcpp.hpp"
#include "std_msgs/msg/int32.hpp"
using namespace std::chrono_literals;
// Node that produces messages.
struct Producer : public rclcpp::Node
{
Producer(const std::string & name, const std::string & output)
: Node(name, rclcpp::NodeOptions().use_intra_process_comms(true))
{
// Create a publisher on the output topic.
pub_ = this->create_publisher<std_msgs::msg::Int32>(output, 10);
std::weak_ptr<std::remove_pointer<decltype(pub_.get())>::type> captured_pub = pub_;
// Create a timer which publishes on the output topic at ~1Hz.
auto callback = [captured_pub]() -> void {
auto pub_ptr = captured_pub.lock();
if (!pub_ptr) {
return;
}
static int32_t count = 0;
std_msgs::msg::Int32::UniquePtr msg(new std_msgs::msg::Int32());
msg->data = count++;
printf(
"Published message with value: %d, and address: 0x%" PRIXPTR "\n", msg->data,
reinterpret_cast<std::uintptr_t>(msg.get()));
pub_ptr->publish(std::move(msg));
};
timer_ = this->create_wall_timer(1s, callback);
}
rclcpp::Publisher<std_msgs::msg::Int32>::SharedPtr pub_;
rclcpp::TimerBase::SharedPtr timer_;
};
// Node that consumes messages.
struct Consumer : public rclcpp::Node
{
Consumer(const std::string & name, const std::string & input)
: Node(name, rclcpp::NodeOptions().use_intra_process_comms(true))
{
// Create a subscription on the input topic which prints on receipt of new messages.
sub_ = this->create_subscription<std_msgs::msg::Int32>(
input,
10,
[](std_msgs::msg::Int32::UniquePtr msg) {
printf(
" Received message with value: %d, and address: 0x%" PRIXPTR "\n", msg->data,
reinterpret_cast<std::uintptr_t>(msg.get()));
});
}
rclcpp::Subscription<std_msgs::msg::Int32>::SharedPtr sub_;
};
int main(int argc, char * argv[])
{
setvbuf(stdout, NULL, _IONBF, BUFSIZ);
rclcpp::init(argc, argv);
rclcpp::executors::SingleThreadedExecutor executor;
auto producer = std::make_shared<Producer>("producer", "number");
auto consumer = std::make_shared<Consumer>("consumer", "number");
executor.add_node(producer);
executor.add_node(consumer);
executor.spin();
rclcpp::shutdown();
return 0;
}
Comme vous pouvez le voir en regardant la fonction main, nous avons un nœud producteur et un nœud consommateur, nous les ajoutons à un seul exécuteur fileté, puis nous appelons spin.
Si vous regardez l’implémentation du nœud « producteur » dans la structure Producteur, vous pouvez voir que nous avons créé un éditeur qui publie sur le sujet « numéro » et un minuteur qui crée périodiquement un nouveau message, imprime son adresse en mémoire et la valeur de son contenu, puis le publie.
Le nœud « consumer » est un peu plus simple, vous pouvez voir son implémentation dans la structure Consumer, car il ne s’abonne qu’au sujet « number » et imprime l’adresse et la valeur du message qu’il reçoit.
On s’attend à ce que le producteur imprime une adresse et une valeur et que le consommateur imprime une adresse et une valeur correspondantes. Cela démontre que la communication intra-processus fonctionne bien et que les copies inutiles sont évitées, du moins pour les graphes simples.
Lançons la démo en exécutant l’exécutable ros2 run intra_process_demo two_node_pipeline (n’oubliez pas de sourcer d’abord le fichier de configuration) :
$ ros2 run intra_process_demo two_node_pipeline
Published message with value: 0, and address: 0x7fb02303faf0
Published message with value: 1, and address: 0x7fb020cf0520
Received message with value: 1, and address: 0x7fb020cf0520
Published message with value: 2, and address: 0x7fb020e12900
Received message with value: 2, and address: 0x7fb020e12900
Published message with value: 3, and address: 0x7fb020cf0520
Received message with value: 3, and address: 0x7fb020cf0520
Published message with value: 4, and address: 0x7fb020e12900
Received message with value: 4, and address: 0x7fb020e12900
Published message with value: 5, and address: 0x7fb02303cea0
Received message with value: 5, and address: 0x7fb02303cea0
[...]
Une chose que vous remarquerez est que les messages défilent à environ un par seconde. C’est parce que nous avons dit au chronomètre de tirer environ une fois par seconde.
De plus, vous avez peut-être remarqué que le premier message (avec la valeur 0) n’a pas de ligne « Message reçu … » correspondante. En effet, la publication/l’abonnement est « le meilleur effort » et nous n’avons aucun comportement de type « verrouillage » activé. Cela signifie que si l’éditeur publie un message avant que l’abonnement ne soit établi, l’abonnement ne recevra pas ce message. Cette condition de concurrence peut entraîner la perte des premiers messages. Dans ce cas, comme ils ne viennent qu’une fois par seconde, généralement seul le premier message est perdu.
Enfin, vous pouvez voir que les lignes « Message publié… » et « Message reçu… » de même valeur ont également la même adresse. Cela montre que l’adresse du message reçu est la même que celle qui a été publiée et qu’il ne s’agit pas d’une copie. C’est parce que nous publions et nous abonnons avec std::unique_ptrs qui permettent de déplacer la propriété d’un message dans le système en toute sécurité. Vous pouvez également publier et vous abonner avec const & et std::shared_ptr, mais la copie zéro ne se produira pas dans ce cas.
La démo du pipeline cyclique
Cette démo est similaire à la précédente, mais au lieu que le producteur crée un nouveau message pour chaque itération, cette démo n’utilise qu’une seule instance de message. Ceci est réalisé en créant un cycle dans le graphe et en « lançant » la communication en faisant publier en externe l’un des nœuds avant de faire tourner l’exécuteur :
#include <chrono>
#include <cinttypes>
#include <cstdio>
#include <memory>
#include <string>
#include <utility>
#include "rclcpp/rclcpp.hpp"
#include "std_msgs/msg/int32.hpp"
using namespace std::chrono_literals;
// This node receives an Int32, waits 1 second, then increments and sends it.
struct IncrementerPipe : public rclcpp::Node
{
IncrementerPipe(const std::string & name, const std::string & in, const std::string & out)
: Node(name, rclcpp::NodeOptions().use_intra_process_comms(true))
{
// Create a publisher on the output topic.
pub = this->create_publisher<std_msgs::msg::Int32>(out, 10);
std::weak_ptr<std::remove_pointer<decltype(pub.get())>::type> captured_pub = pub;
// Create a subscription on the input topic.
sub = this->create_subscription<std_msgs::msg::Int32>(
in,
10,
[captured_pub](std_msgs::msg::Int32::UniquePtr msg) {
auto pub_ptr = captured_pub.lock();
if (!pub_ptr) {
return;
}
printf(
"Received message with value: %d, and address: 0x%" PRIXPTR "\n", msg->data,
reinterpret_cast<std::uintptr_t>(msg.get()));
printf(" sleeping for 1 second...\n");
if (!rclcpp::sleep_for(1s)) {
return; // Return if the sleep failed (e.g. on ctrl-c).
}
printf(" done.\n");
msg->data++; // Increment the message's data.
printf(
"Incrementing and sending with value: %d, and address: 0x%" PRIXPTR "\n", msg->data,
reinterpret_cast<std::uintptr_t>(msg.get()));
pub_ptr->publish(std::move(msg)); // Send the message along to the output topic.
});
}
rclcpp::Publisher<std_msgs::msg::Int32>::SharedPtr pub;
rclcpp::Subscription<std_msgs::msg::Int32>::SharedPtr sub;
};
int main(int argc, char * argv[])
{
setvbuf(stdout, NULL, _IONBF, BUFSIZ);
rclcpp::init(argc, argv);
rclcpp::executors::SingleThreadedExecutor executor;
// Create a simple loop by connecting the in and out topics of two IncrementerPipe's.
// The expectation is that the address of the message being passed between them never changes.
auto pipe1 = std::make_shared<IncrementerPipe>("pipe1", "topic1", "topic2");
auto pipe2 = std::make_shared<IncrementerPipe>("pipe2", "topic2", "topic1");
rclcpp::sleep_for(1s); // Wait for subscriptions to be established to avoid race conditions.
// Publish the first message (kicking off the cycle).
std::unique_ptr<std_msgs::msg::Int32> msg(new std_msgs::msg::Int32());
msg->data = 42;
printf(
"Published first message with value: %d, and address: 0x%" PRIXPTR "\n", msg->data,
reinterpret_cast<std::uintptr_t>(msg.get()));
pipe1->pub->publish(std::move(msg));
executor.add_node(pipe1);
executor.add_node(pipe2);
executor.spin();
rclcpp::shutdown();
return 0;
}
Contrairement à la démo précédente, cette démo utilise un seul nœud, instancié deux fois avec des noms et des configurations différents. Le graphique finit par être pipe1 -> pipe2 -> pipe1 … dans une boucle.
La ligne pipe1->pub->publish(msg); lance le processus, mais à partir de là, les messages sont transmis entre les nœuds par chacun appelant la publication dans son propre rappel d’abonnement.
L’attente ici est que les nœuds transmettent le message dans les deux sens, une fois par seconde, en incrémentant la valeur du message à chaque fois. Comme le message est publié et souscrit en tant que unique_ptr, le même message créé au début est utilisé en permanence.
Pour tester ces attentes, exécutons-le :
$ ros2 run intra_process_demo cyclic_pipeline
Published first message with value: 42, and address: 0x7fd2ce0a2bc0
Received message with value: 42, and address: 0x7fd2ce0a2bc0
sleeping for 1 second...
done.
Incrementing and sending with value: 43, and address: 0x7fd2ce0a2bc0
Received message with value: 43, and address: 0x7fd2ce0a2bc0
sleeping for 1 second...
done.
Incrementing and sending with value: 44, and address: 0x7fd2ce0a2bc0
Received message with value: 44, and address: 0x7fd2ce0a2bc0
sleeping for 1 second...
done.
Incrementing and sending with value: 45, and address: 0x7fd2ce0a2bc0
Received message with value: 45, and address: 0x7fd2ce0a2bc0
sleeping for 1 second...
done.
Incrementing and sending with value: 46, and address: 0x7fd2ce0a2bc0
Received message with value: 46, and address: 0x7fd2ce0a2bc0
sleeping for 1 second...
done.
Incrementing and sending with value: 47, and address: 0x7fd2ce0a2bc0
Received message with value: 47, and address: 0x7fd2ce0a2bc0
sleeping for 1 second...
[...]
Vous devriez voir des nombres toujours croissants à chaque itération, en commençant par 42… car 42, et tout le temps ça réutilise le même message, comme en témoignent les adresses des pointeurs qui ne changent pas, ce qui évite les copies inutiles.
La démonstration du pipeline d’images
Dans cette démo, nous utiliserons OpenCV pour capturer, annoter, puis afficher des images.
Note
Si vous êtes sur macOS et que ces exemples ne fonctionnent pas ou que vous recevez une erreur telle que ddsi_conn_write failed -1, vous devrez alors augmenter la taille des paquets UDP à l’échelle de votre système :
$ sudo sysctl -w net.inet.udp.recvspace=209715
$ sudo sysctl -w net.inet.udp.maxdgram=65500
Ces modifications ne persisteront pas après un redémarrage.
Conduite simplifiée
Nous aurons d’abord un pipeline de trois nœuds, organisés comme tels : camera_node -> watermark_node -> image_view_node
Le camera_node lit à partir de l’appareil photo 0 sur votre ordinateur, écrit des informations sur l’image et les publie. Le watermark_node s’abonne à la sortie du camera_node et ajoute plus de texte avant de le publier également. Enfin, le image_view_node s’abonne à la sortie du watermark_node, écrit plus de texte sur l’image puis le visualise avec cv::imshow.
Dans chaque nœud, l’adresse du message qui est envoyé, ou qui a été reçu, ou les deux, est écrite dans l’image. Les nœuds de filigrane et de vue d’image sont conçus pour modifier l’image sans la copier et donc les adresses imprimées sur l’image doivent toutes être les mêmes tant que les nœuds sont dans le même processus et que le graphique reste organisé dans un pipeline comme esquissé ci-dessus.
Note
Sur certains systèmes (nous l’avons vu sur Linux), l’adresse imprimée à l’écran peut ne pas changer. C’est parce que le même pointeur unique est réutilisé. Dans cette situation, le pipeline est toujours en cours d’exécution.
Lançons la démo en exécutant l’exécutable suivant :
ros2 run intra_process_demo image_pipeline_all_in_one
Vous devriez voir quelque chose comme ceci :

Vous pouvez interrompre le rendu de l’image en appuyant sur la barre d’espace et vous pouvez reprendre en appuyant à nouveau sur la barre d’espace. Vous pouvez également appuyer sur q ou ESC pour quitter.
Si vous mettez en pause la visionneuse d’images, vous devriez pouvoir comparer les adresses écrites sur l’image et voir qu’elles sont identiques.
Pipeline avec deux visionneuses d’images
Regardons maintenant un exemple comme celui ci-dessus, sauf qu’il a deux nœuds de vue d’image. Tous les nœuds sont toujours dans le même processus, mais maintenant deux fenêtres d’affichage d’image devraient apparaître. (Remarque pour les utilisateurs de macOS : vos fenêtres d’affichage d’image peuvent se superposer). Exécutons-le avec la commande :
ros2 run intra_process_demo image_pipeline_with_two_image_view
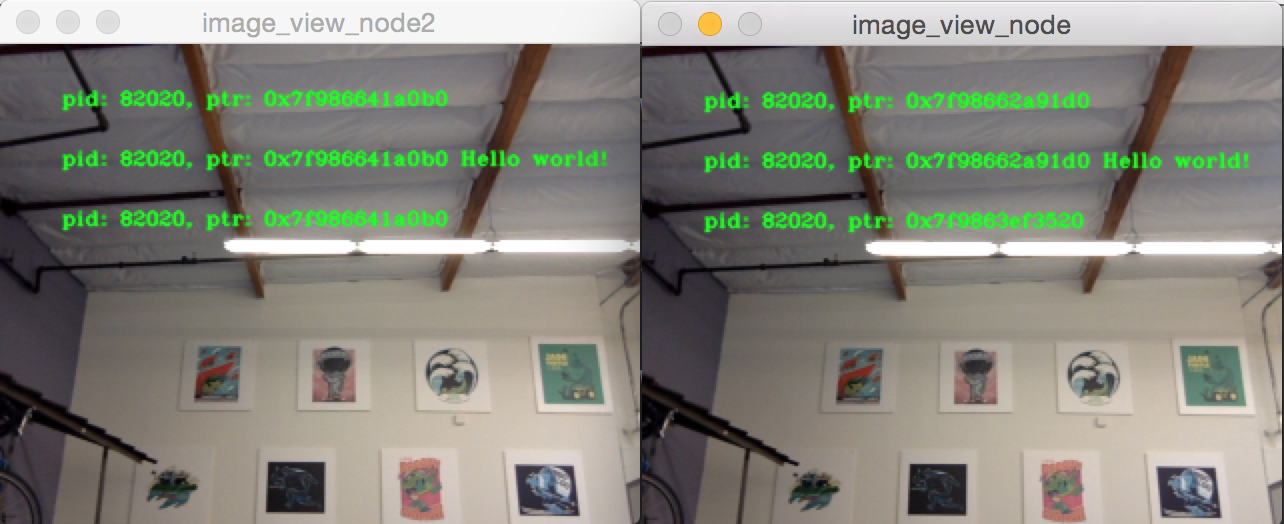
Tout comme le dernier exemple, vous pouvez interrompre le rendu avec la barre d’espace et continuer en appuyant une seconde fois sur la barre d’espace. Vous pouvez arrêter la mise à jour pour inspecter les pointeurs écrits à l’écran.
Comme vous pouvez le voir dans l’exemple d’image ci-dessus, nous avons une image avec tous les pointeurs identiques, puis une autre image avec les mêmes pointeurs que la première image pour les deux premières entrées, mais le dernier pointeur sur la deuxième image est différent. Pour comprendre pourquoi cela se produit, considérez la topologie du graphique :
camera_node -> watermark_node -> image_view_node
-> image_view_node2
Le lien entre le camera_node et le watermark_node peut utiliser le même pointeur sans copier car il n’y a qu’un seul abonnement intra-processus auquel le message doit être livré. Mais pour le lien entre le watermark_node et les deux nœuds de vue d’image, la relation est un à plusieurs, donc si les nœuds de vue d’image utilisaient des rappels unique_ptr, il serait alors impossible de livrer la propriété du même pointeur vers les deux. Il peut cependant être livré à l’un d’entre eux. Celui qui obtiendrait le pointeur d’origine n’est pas défini, mais est simplement le dernier à être livré.
Notez que les nœuds de vue d’image ne sont pas abonnés aux rappels unique_ptr. Au lieu de cela, ils sont abonnés avec const shared_ptrs. Cela signifie que le système délivre le même shared_ptr aux deux rappels. Lorsque le premier abonnement intraprocessus est géré, le unique_ptr stocké en interne est promu en shared_ptr. Chacun des rappels recevra la propriété partagée du même message.
Pipeline avec visualiseur interprocessus
Une autre chose importante à faire est d’éviter l’interruption du comportement de copie zéro intra-processus lorsque des abonnements inter-processus sont effectués. Pour tester cela, nous pouvons exécuter la première démo de pipeline d’images, image_pipeline_all_in_one, puis exécuter une instance du seul image_view_node (n’oubliez pas de les préfixer avec ros2 run intra_process_demo dans le Terminal). Cela ressemblera à ceci :
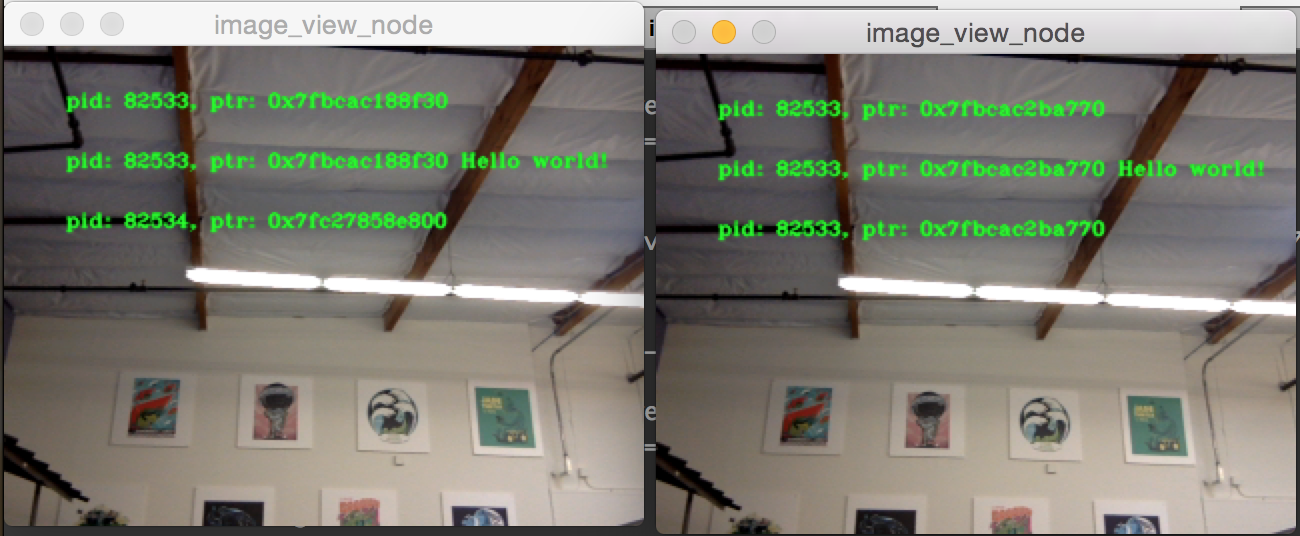
Il est difficile de mettre en pause les deux images en même temps afin que les images ne soient pas alignées, mais la chose importante à noter est que la vue d’image image_pipeline_all_in_one affiche la même adresse pour chaque étape. Cela signifie que la copie zéro intra-processus est conservée même lorsqu’une vue externe est également souscrite. Vous pouvez également voir que la vue d’image interprocessus a des ID de processus différents pour les deux premières lignes de texte et l’ID de processus de la visionneuse d’images autonome dans la troisième ligne de texte.